Microsoft ra mắt mô hình ngôn ngữ Phi-3.5 mạnh mẽ, vượt mặt Google, OpenAI và nhiều đối thủ khác
Microsoft không hề ngủ quên trên chiến thắng của mình trong lĩnh vực AI sau thành công của mối quan hệ hợp tác với OpenAI.
Trái lại, công ty có trụ sở tại Redmond, Washington này hôm nay đã tạo nên cơn sốt với việc phát hành 3 mô hình mới thuộc dòng mô hình ngôn ngữ/đa phương thức AI Phi đang ngày càng phát triển.
Ba mô hình Phi 3.5 mới bao gồm Phi-3.5-mini-instruct với 3,82 tỷ tham số, Phi-3.5-MoE-instruct với 41,9 tỷ tham số và Phi-3.5-vision-instruct với 4,15 tỷ tham số, mỗi mô hình được thiết kế lần lượt cho các tác vụ suy luận cơ bản/nhanh, suy luận phức tạp hơn và thị giác (phân tích hình ảnh và video).
Cả ba mô hình đều có sẵn để các nhà phát triển tải xuống, sử dụng và tinh chỉnh trên Hugging Face theo Giấy phép MIT mang thương hiệu Microsoft, cho phép sử dụng và sửa đổi cho mục đích thương mại mà không bị hạn chế.
Điều đáng kinh ngạc là cả ba mô hình đều tự hào có hiệu suất gần như tiên tiến nhất trong một số bài kiểm tra benchmark của bên thứ ba, thậm chí còn đánh bại các nhà cung cấp AI khác bao gồm Gemini 1.5 Flash của Google, Llama 3.1 của Meta và thậm chí cả GPT-4o của OpenAI trong một số trường hợp.
Hiệu suất đó, kết hợp với giấy phép mở cho phép sử dụng rộng rãi, đã khiến mọi người ca ngợi Microsoft trên mạng xã hội X:
Let’s gooo.. Microsoft just release Phi 3.5 mini, MoE and vision with 128K context, multilingual & MIT license! MoE beats Gemini flash, Vision competitive with GPT4o🔥
> Mini with 3.8B parameters, beats Llama3.1 8B and Mistral 7B and competitive with Mistral NeMo 12B
>… pic.twitter.com/7QJYOSSdyX
Hãy cùng đánh giá ngắn gọn từng mô hình mới được phát hành hôm nay, dựa trên ghi chú phát hành của chúng được đăng trên Hugging Face.
Phi-3.5 Mini Instruct: Tối ưu hóa cho môi trường hạn chế về tài nguyên tính toán
Mô hình Phi-3.5 Mini Instruct là một mô hình AI gọn nhẹ với 3,8 tỷ tham số, được thiết kế để tuân thủ hướng dẫn và hỗ trợ độ dài ngữ cảnh 128 nghìn token.
Mô hình này lý tưởng cho các tình huống yêu cầu khả năng suy luận mạnh mẽ trong môi trường hạn chế về bộ nhớ hoặc khả năng tính toán, bao gồm các tác vụ như tạo mã, giải toán và suy luận dựa trên logic.
Mặc dù có kích thước nhỏ gọn, mô hình Phi-3.5 Mini Instruct thể hiện hiệu suất cạnh tranh trong các tác vụ đàm thoại đa ngôn ngữ và đa lượt, phản ánh những cải tiến đáng kể so với các phiên bản tiền nhiệm.
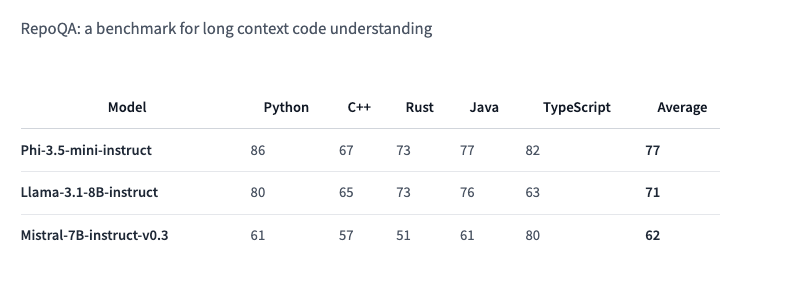
Nó tự hào có hiệu suất gần như tiên tiến nhất trên một số điểm chuẩn và vượt qua các mô hình có kích thước tương tự khác (Llama-3.1-8B-instruct và Mistral-7B-instruct) trên điểm chuẩn RepoQA, đo lường “khả năng hiểu mã ngữ cảnh dài”.
Phi-3.5 MoE: ‘Hỗn hợp chuyên gia’ của Microsoft
Mô hình Phi-3.5 MoE (Mixture of Experts) dường như là mô hình đầu tiên thuộc lớp mô hình này của công ty, kết hợp nhiều loại mô hình khác nhau thành một, mỗi loại chuyên về các tác vụ khác nhau.
Mô hình này tận dụng kiến trúc với 42 tỷ tham số hoạt động và hỗ trợ độ dài ngữ cảnh 128 nghìn token, cung cấp hiệu suất AI có khả năng mở rộng cho các ứng dụng đòi hỏi khắt khe. Tuy nhiên, nó chỉ hoạt động với 6,6 tỷ tham số hoạt động, theo tài liệu HuggingFace.
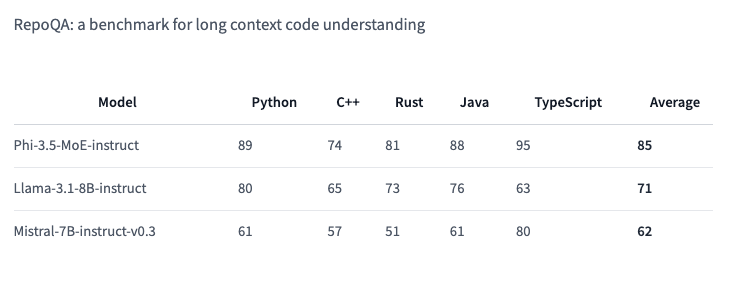
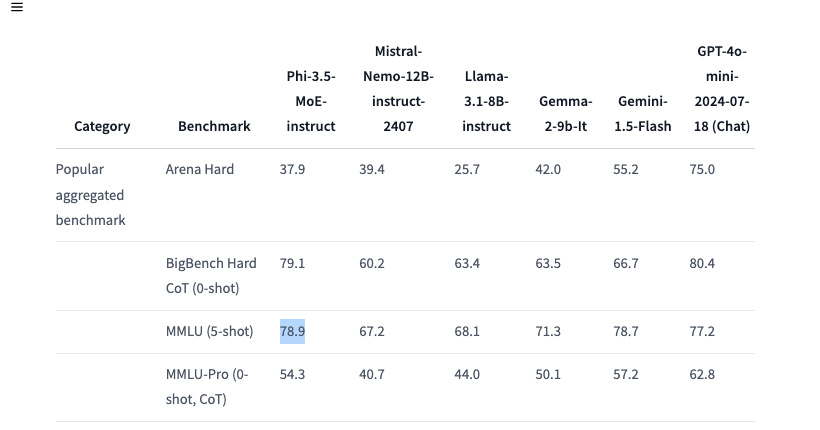
Được thiết kế để vượt trội trong các tác vụ suy luận khác nhau, Phi-3.5 MoE mang đến hiệu suất mạnh mẽ về mã, toán học và hiểu ngôn ngữ đa ngôn ngữ, thường vượt trội hơn các mô hình lớn hơn trong các điểm chuẩn cụ thể, bao gồm cả RepoQA: Ấn tượng hơn, nó còn đánh bại GPT-4o mini trên MMLU 5-shot (Hiểu biết ngôn ngữ đa nhiệm lớn) trên các môn học như STEM, nhân văn, khoa học xã hội, ở các cấp độ chuyên môn khác nhau. Kiến trúc độc đáo của mô hình MoE cho phép nó duy trì hiệu quả trong khi xử lý các tác vụ AI phức tạp trên nhiều ngôn ngữ.
Phi-3.5 Vision Instruct: Suy luận đa phương thức tiên tiến
Hoàn thiện bộ ba là mô hình Phi-3.5 Vision Instruct, tích hợp cả khả năng xử lý văn bản và hình ảnh.
Mô hình đa phương thức này đặc biệt phù hợp cho các tác vụ như hiểu hình ảnh chung, nhận dạng ký tự quang học, hiểu biểu đồ và bảng, tóm tắt video.
Giống như các mô hình khác trong dòng Phi-3.5, Vision Instruct hỗ trợ độ dài ngữ cảnh 128 nghìn token, cho phép nó quản lý các tác vụ thị giác phức tạp, đa khung hình.
Microsoft nhấn mạnh rằng mô hình này được đào tạo bằng cách kết hợp các bộ dữ liệu có sẵn công khai được tổng hợp và lọc, tập trung vào dữ liệu chất lượng cao, dày đặc về lý luận.
Huấn luyện bộ ba Phi mới
Mô hình Phi-3.5 Mini Instruct được đào tạo trên 3,4 nghìn tỷ token bằng cách sử dụng 512 GPU H100-80G trong hơn 10 ngày, trong khi mô hình Vision Instruct được đào tạo trên 500 tỷ token bằng cách sử dụng 256 GPU A100-80G trong hơn 6 ngày.
Mô hình Phi-3.5 MoE, có kiến trúc hỗn hợp chuyên gia, được đào tạo trên 4,9 nghìn tỷ token với 512 GPU H100-80G trong hơn 23 ngày.
Nguồn mở theo Giấy phép MIT
Cả ba mô hình Phi-3.5 đều có sẵn theo Giấy phép MIT, phản ánh cam kết của Microsoft trong việc hỗ trợ cộng đồng nguồn mở.
Giấy phép này cho phép các nhà phát triển tự do sử dụng, sửa đổi, hợp nhất, xuất bản, phân phối, cấp phép lại hoặc bán bản sao phần mềm.
Giấy phép cũng bao gồm một tuyên bố từ chối trách nhiệm rằng phần mềm được cung cấp “nguyên trạng”, không có bất kỳ bảo hành nào. Microsoft và những người giữ bản quyền khác không chịu trách nhiệm cho bất kỳ khiếu nại, thiệt hại hoặc trách nhiệm pháp lý nào khác có thể phát sinh từ việc sử dụng phần mềm.
Việc Microsoft phát hành dòng Phi-3.5 thể hiện một bước tiến đáng kể trong việc phát triển AI đa ngôn ngữ và đa phương thức.
Bằng cách cung cấp các mô hình này theo giấy phép nguồn mở, Microsoft trao quyền cho các nhà phát triển tích hợp các khả năng AI tiên tiến vào các ứng dụng của họ, thúc đẩy sự đổi mới trong cả lĩnh vực thương mại và nghiên cứu.





: Ai đang dẫn đầu trong năm 2024?")
