Tin tức AI
Meta ra mắt mô hình AI ‘mã nguồn mở’ lớn nhất từ trước đến nay

Meta vừa công bố mô hình AI mã nguồn mở mới nhất và lớn nhất của họ.
Hôm nay, Meta cho biết họ đang phát hành Llama 3.1 405B, một mô hình chứa 405 tỷ tham số. Các tham số tương ứng với khả năng giải quyết vấn đề của mô hình và các mô hình có nhiều tham số thường hoạt động tốt hơn so với các mô hình có ít tham số hơn.
Với 405 tỷ tham số, Llama 3.1 405B không phải là mô hình mã nguồn mở lớn nhất tuyệt đối hiện có, nhưng nó là mô hình lớn nhất trong những năm gần đây. Được đào tạo bằng cách sử dụng 16.000 GPU Nvidia H100, nó cũng được hưởng lợi từ các kỹ thuật đào tạo và phát triển mới hơn mà Meta tuyên bố là giúp nó cạnh tranh với các mô hình độc quyền hàng đầu như GPT-4o của OpenAI và Claude 3.5 Sonnet của Anthropic (với một vài cảnh báo).
Cũng như các mô hình trước đây của Meta, Llama 3.1 405B có sẵn để tải xuống hoặc sử dụng trên các nền tảng đám mây như AWS, Azure và Google Cloud. Nó cũng đang được sử dụng trên WhatsApp và Meta.ai, nơi nó cung cấp năng lượng cho trải nghiệm chatbot cho người dùng tại Hoa Kỳ.
Mới và cải tiến
Giống như các mô hình AI tạo sinh mã nguồn mở và đóng khác, Llama 3.1 405B có thể thực hiện một loạt các tác vụ khác nhau, từ viết mã và trả lời các câu hỏi toán học cơ bản đến tóm tắt tài liệu bằng tám thứ tiếng (tiếng Anh, tiếng Đức, tiếng Pháp, tiếng Ý, tiếng Bồ Đào Nha, tiếng Hindi, tiếng Tây Ban Nha và tiếng Thái).
Nó chỉ dành cho văn bản, nghĩa là chẳng hạn, nó không thể trả lời các câu hỏi về hình ảnh, nhưng hầu hết các khối lượng công việc dựa trên văn bản – hãy nghĩ đến việc phân tích các tệp như PDF và bảng tính – đều nằm trong tầm tay của nó.
Meta muốn mọi người biết rằng họ đang thử nghiệm đa phương thức. Trong một bài báo được xuất bản hôm nay, các nhà nghiên cứu tại công ty đã viết rằng họ đang tích cực phát triển các mô hình Llama có thể nhận dạng hình ảnh và video, đồng thời hiểu (và tạo) lời nói. Tuy nhiên, những mô hình này vẫn chưa sẵn sàng để phát hành công khai.
Để đào tạo Llama 3.1 405B, Meta đã sử dụng tập dữ liệu gồm 15 nghìn tỷ mã thông báo có niên đại đến năm 2024 (mã thông báo là các phần của từ mà mô hình có thể dễ dàng tiếp thu hơn so với toàn bộ từ và 15 nghìn tỷ mã thông báo được dịch thành 750 tỷ từ).
Nó không phải là một bộ đào tạo mới, vì Meta đã sử dụng bộ cơ sở để đào tạo các mô hình Llama trước đó, nhưng công ty tuyên bố rằng họ đã tinh chỉnh các quy trình quản lý dữ liệu của mình và áp dụng các phương pháp đảm bảo chất lượng và lọc dữ liệu “nghiêm ngặt” hơn trong việc phát triển mô hình này.
Công ty cũng đã sử dụng dữ liệu tổng hợp (dữ liệu được tạo bởi các mô hình AI khác) để tinh chỉnh Llama 3.1 405B.
Hầu hết các nhà cung cấp AI lớn, bao gồm OpenAI và Anthropic, đang khám phá các ứng dụng của dữ liệu tổng hợp để mở rộng quy mô đào tạo AI của họ, nhưng một số chuyên gia tin rằng dữ liệu tổng hợp nên là lựa chọn cuối cùng do khả năng làm trầm trọng thêm thành kiến mô hình của nó.
Về phần mình, Meta khẳng định rằng họ đã “cân bằng cẩn thận” dữ liệu đào tạo của Llama 3.1 405B, nhưng từ chối tiết lộ chính xác dữ liệu đến từ đâu (ngoài các trang web và tệp web công cộng).
Nhiều nhà cung cấp AI tạo sinh coi dữ liệu đào tạo là lợi thế cạnh tranh và do đó, hãy giữ bí mật nó và bất kỳ thông tin nào liên quan đến nó. Nhưng chi tiết dữ liệu đào tạo cũng là nguồn tiềm ẩn của các vụ kiện liên quan đến IP, một lý do khác khiến các công ty không muốn tiết lộ nhiều.
Trong bài báo nói trên, các nhà nghiên cứu của Meta đã viết rằng so với các mô hình Llama trước đó, Llama 3.1 405B được đào tạo trên nhiều dữ liệu không phải tiếng Anh hơn (để cải thiện hiệu suất của nó trên các ngôn ngữ không phải tiếng Anh), nhiều “dữ liệu toán học” và mã hơn (để cải thiện mô hình kỹ năng lập luận toán học) và dữ liệu web gần đây (để củng cố kiến thức của nó về các sự kiện hiện tại).
Báo cáo gần đây của Reuters tiết lộ rằng Meta đã có lúc sử dụng sách điện tử có bản quyền để đào tạo AI bất chấp cảnh báo của chính luật sư của họ.
Công ty gây tranh cãi khi đào tạo AI của mình trên các bài đăng, ảnh và chú thích trên Instagram và Facebook, đồng thời khiến người dùng khó từ chối. Hơn nữa, Meta, cùng với OpenAI, là đối tượng của một vụ kiện đang diễn ra do các tác giả, bao gồm cả diễn viên hài Sarah Silverman, đưa ra về cáo buộc các công ty sử dụng trái phép dữ liệu có bản quyền để đào tạo mô hình.
“Dữ liệu đào tạo, theo nhiều cách, giống như công thức bí mật và nước sốt để xây dựng những mô hình này”, Ragavan Srinivasan, VP quản lý chương trình AI tại Meta, nói với TechCrunch trong một cuộc phỏng vấn. “Và vì vậy, từ quan điểm của chúng tôi, chúng tôi đã đầu tư rất nhiều vào việc này. Và nó sẽ là một trong những thứ mà chúng tôi sẽ tiếp tục tinh chỉnh.”
Bối cảnh rộng hơn và các công cụ mới
Llama 3.1 405B có cửa sổ ngữ cảnh lớn hơn so với các mô hình Llama trước đây: 128.000 mã thông báo, hoặc gần bằng độ dài của một cuốn sách 50 trang.
Ngữ cảnh hoặc cửa sổ ngữ cảnh của mô hình đề cập đến dữ liệu đầu vào (ví dụ: văn bản) mà mô hình xem xét trước khi tạo đầu đầu ra (ví dụ: văn bản bổ sung).
Một trong những lợi thế của các mô hình có ngữ cảnh lớn hơn là chúng có thể tóm tắt các đoạn văn bản và tệp dài hơn. Khi cung cấp năng lượng cho chatbot, những mô hình như vậy cũng ít có khả năng quên các chủ đề đã được thảo luận gần đây.
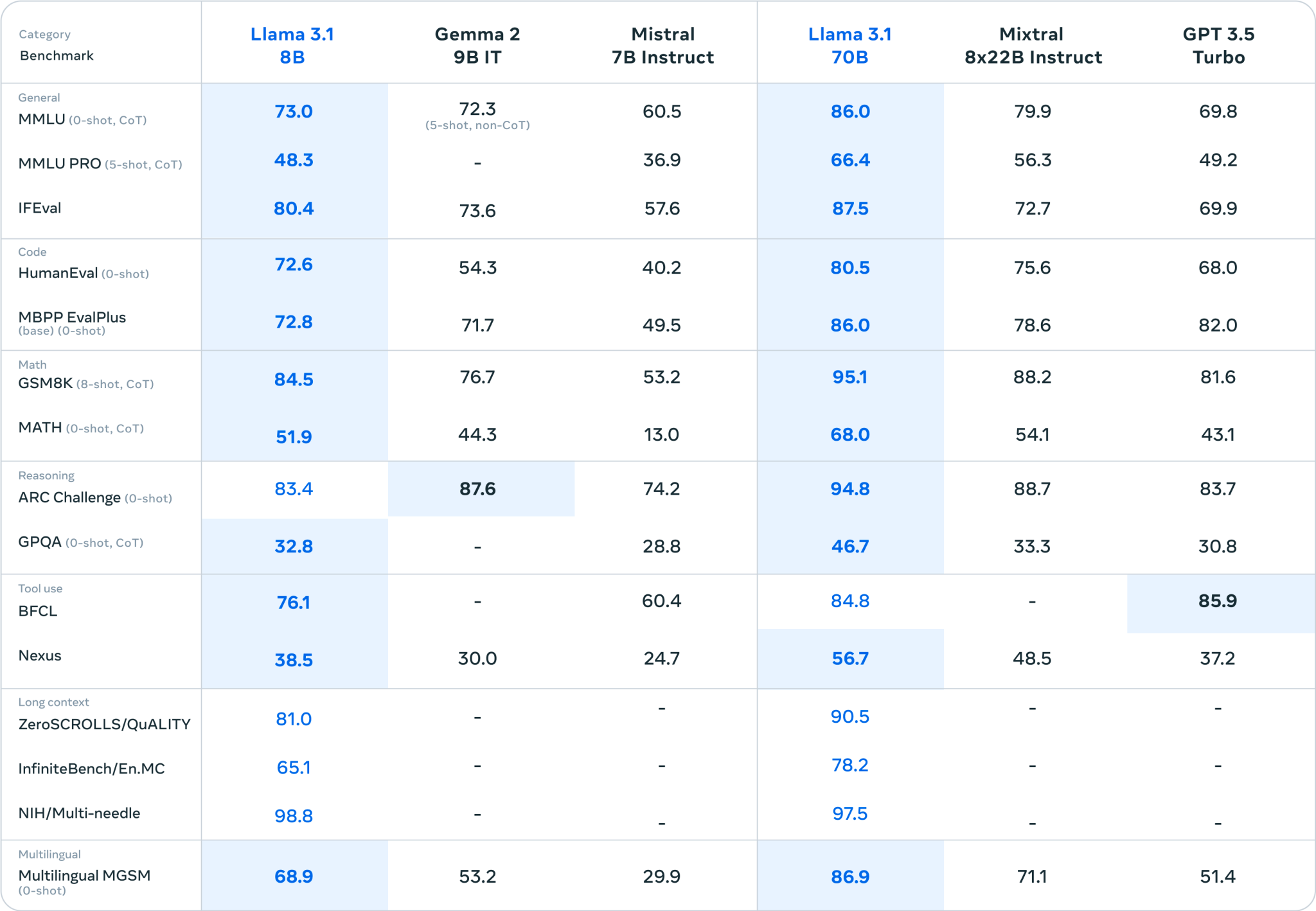
Hai mô hình mới, nhỏ hơn mà Meta ra mắt hôm nay, Llama 3.1 8B và Llama 3.1 70B — các phiên bản cập nhật của mô hình Llama 3 8B và Llama 3 70B của công ty được phát hành vào tháng 4 — cũng có cửa sổ ngữ cảnh 128.000 mã thông báo.
Ngữ cảnh của các mô hình trước đó đạt tối đa 8.000 mã thông báo, điều này làm cho bản nâng cấp này khá đáng kể – giả sử các mô hình Llama mới có thể lý luận hiệu quả trên tất cả ngữ cảnh đó.
Tất cả các mô hình Llama 3.1 đều có thể sử dụng các công cụ, ứng dụng và API của bên thứ ba để hoàn thành các tác vụ, giống như các mô hình cạnh tranh từ Anthropic và OpenAI.
Ngay khi xuất xưởng, chúng được đào tạo để khai thác Brave Search để trả lời các câu hỏi về các sự kiện gần đây, API Wolfram Alpha cho các truy vấn liên quan đến toán học và khoa học, và trình thông dịch Python để xác thực mã.
Ngoài ra, Meta tuyên bố các mô hình Llama 3.1 có thể sử dụng một số công cụ nhất định mà chúng chưa từng thấy trước đây – ở một mức độ nào đó.
Xây dựng một hệ sinh thái
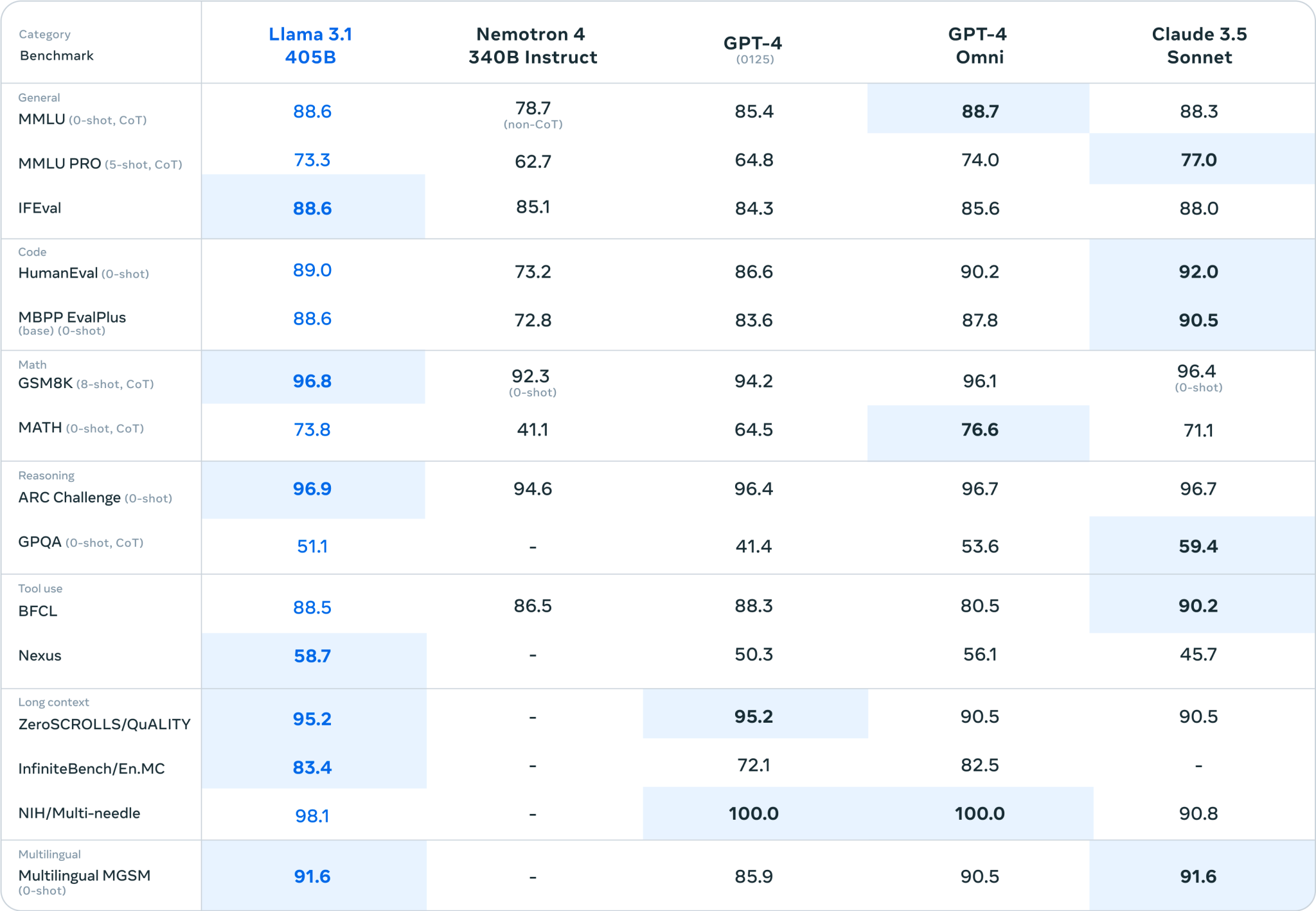
Nếu các điểm chuẩn là đáng tin cậy (không phải là các điểm chuẩn là tất cả trong AI tổng quát), thì Llama 3.1 405B thực sự là một mô hình rất có khả năng.
Đó sẽ là một điều tốt, xem xét một số hạn chế quá rõ ràng của các mô hình Llama thế hệ trước.
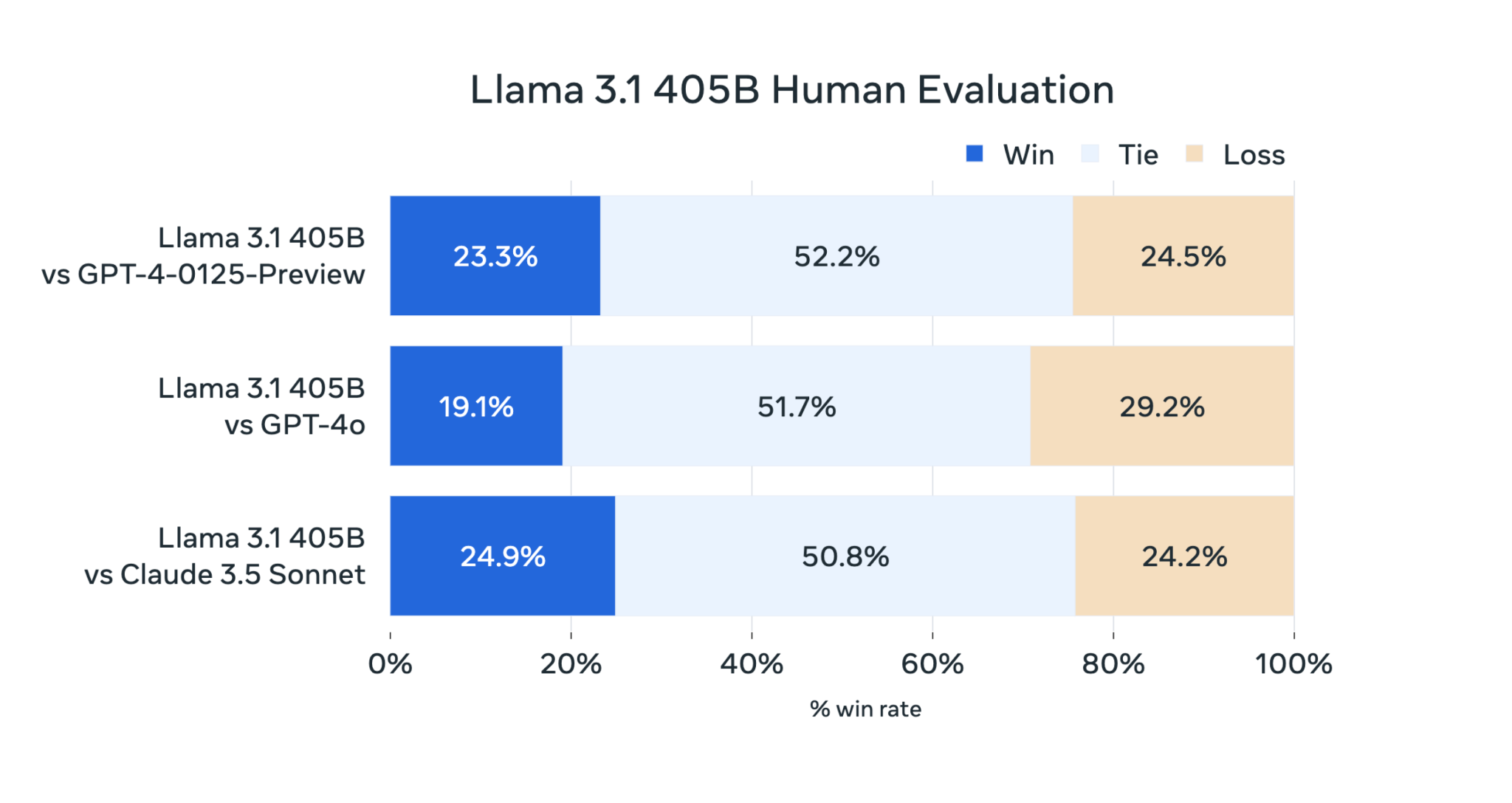
Llama 3 405B hoạt động ngang bằng với GPT-4 của OpenAI và đạt được “kết quả hỗn hợp” so với GPT-4o và Claude 3.5 Sonnet, theo những người đánh giá là con người mà Meta đã thuê, bài báo lưu ý.
Mặc dù Llama 3 405B thực thi mã và tạo biểu đồ tốt hơn GPT-4o, nhưng khả năng đa ngôn ngữ của nó nhìn chung yếu hơn và Llama 3 405B kém Claude 3.5 Sonnet về lập trình và lý luận chung.
Và bởi vì kích thước của nó, nó cần phần cứng mạnh mẽ để chạy. Meta khuyên bạn nên có ít nhất một nút máy chủ.
Đó có lẽ là lý do tại sao Meta lại thúc đẩy các mô hình mới nhỏ hơn của mình, Llama 3.1 8B và Llama 3.1 70B, cho các ứng dụng đa năng như cung cấp năng lượng cho chatbot và tạo mã.
Công ty cho biết, Llama 3.1 405B được dành riêng cho việc chắt lọc mô hình – quá trình chuyển giao kiến thức từ một mô hình lớn sang một mô hình nhỏ hơn, hiệu quả hơn – và tạo dữ liệu tổng hợp để đào tạo (hoặc tinh chỉnh) các mô hình thay thế.
Để khuyến khích trường hợp sử dụng dữ liệu tổng hợp, Meta cho biết họ đã cập nhật giấy phép của Llama để cho phép các nhà phát triển sử dụng đầu đầu ra từ dòng mô hình Llama 3.1 để phát triển các mô hình tạo sinh AI của bên thứ ba (liệu đó có phải là ý tưởng hay hay không còn phải tranh luận).
Điều quan trọng là giấy phép vẫn hạn chế cách các nhà phát triển triển khai các mô hình Llama: Các nhà phát triển ứng dụng có hơn 700 triệu người dùng hàng tháng phải yêu cầu giấy phép đặc biệt từ Meta mà công ty sẽ cấp theo quyết định của mình.
Sự thay đổi đó trong việc cấp phép xung quanh đầu đầu ra, làm dịu đi một lời chỉ trích chính đối với các mô hình của Meta trong cộng đồng AI, là một phần trong nỗ lực mạnh mẽ của công ty nhằm giành thị phần trong AI tổng quát.
Bên cạnh dòng Llama 3.1, Meta đang phát hành cái mà họ gọi là “hệ thống tham chiếu” và các công cụ an toàn mới — một số trong số này chặn các lời nhắc có thể khiến các mô hình Llama hoạt động theo những cách không thể đoán trước hoặc không mong muốn — để khuyến khích các nhà phát triển sử dụng Llama ở nhiều nơi hơn.
Công ty cũng đang xem trước và xin ý kiến về Llama Stack, API sắp ra mắt cho các công cụ có thể được sử dụng để tinh chỉnh các mô hình Llama, tạo dữ liệu tổng hợp với Llama và xây dựng các ứng dụng “đại lý” — các ứng dụng được cung cấp bởi Llama có thể thay mặt người dùng.
“Chúng tôi đã nghe đi nghe lại từ các nhà phát triển là sự quan tâm đến việc tìm hiểu cách thực sự triển khai [các mô hình Llama] trong sản xuất”, Srinivasan nói. “Vì vậy, chúng tôi đang cố gắng bắt đầu cung cấp cho họ một loạt các công cụ và tùy chọn khác nhau.”
Cuộc chơi giành thị phần
Trong một bức thư ngỏ được xuất bản sáng nay, CEO của Meta, Mark Zuckerberg, đã vạch ra tầm nhìn cho tương lai, trong đó các công cụ và mô hình AI tiếp cận tay của nhiều nhà phát triển hơn trên khắp thế giới, đảm bảo mọi người đều được hưởng “lợi ích và cơ hội” của AI.
Nó được che giấu một cách rất nhân ái, nhưng ẩn ý trong bức thư là mong muốn của Zuckerberg rằng những công cụ và mô hình này sẽ do Meta tạo ra.
Meta đang chạy đua để bắt kịp các công ty như OpenAI và Anthropic, và họ đang sử dụng một chiến lược đã được thử nghiệm và đúng đắn: cung cấp công cụ miễn phí để nuôi dưỡng hệ sinh thái và sau đó từ từ thêm các sản phẩm và dịch vụ, một số trả phí, lên trên.
Việc chi hàng tỷ đô la cho các mô hình mà sau đó nó có thể thương mại hóa cũng có tác dụng hạ giá của các đối thủ cạnh tranh của Meta và phổ biến rộng rãi phiên bản AI của công ty.
Nó cũng cho phép công ty kết hợp những cải tiến từ cộng đồng nguồn mở vào các mô hình tương lai của mình.
Llama chắc chắn đã thu hút sự chú ý của các nhà phát triển. Meta tuyên bố các mô hình Llama đã được tải xuống hơn 300 triệu lần và hơn 20.000 mô hình phái sinh từ Llama đã được tạo ra cho đến nay.
Đừng nhầm lẫn, Meta đang chơi để giữ chân. Họ đang chi hàng triệu đô la để vận động hành lang các nhà quản lý đi vòng quanh hương vị “mở” ưa thích của họ đối với AI tạo sinh.
Không mô hình Llama 3.1 nào giải quyết được các vấn đề khó giải quyết với công nghệ AI tạo sinh ngày nay, chẳng hạn như xu hướng tạo ra mọi thứ và đưa ra dữ liệu đào tạo có vấn đề.
Nhưng họ thực hiện một trong những mục tiêu chính của Meta: trở thành đồng nghĩa với AI tạo sinh.
Có những chi phí cho việc này. Trong bài báo nghiên cứu, các đồng tác giả — lặp lại những bình luận gần đây của Zuckerberg — thảo luận về các vấn đề về độ tin cậy liên quan đến năng lượng với việc đào tạo các mô hình AI tạo sinh ngày càng phát triển của Meta.
“Trong quá trình đào tạo, hàng chục nghìn GPU có thể tăng hoặc giảm mức tiêu thụ điện năng cùng một lúc, chẳng hạn như do tất cả các GPU đang chờ điểm kiểm tra hoặc thông tin liên lạc tập thể kết thúc, hoặc quá trình khởi động hoặc tắt toàn bộ công việc đào tạo”, họ viết. “Khi điều này xảy ra, nó có thể dẫn đến sự dao động tức thời về mức tiêu thụ điện năng trên toàn trung tâm dữ liệu theo thứ tự hàng chục megawatt, kéo căng giới hạn của lưới điện. Đây là một thách thức liên tục đối với chúng tôi khi chúng tôi mở rộng quy mô đào tạo cho các mô hình Llama lớn hơn nữa trong tương lai.”
Người ta hy vọng rằng việc đào tạo những mô hình lớn hơn đó sẽ không buộc nhiều công ty tiện ích phải duy trì các nhà máy nhiệt điện than cũ kỹ.





