Alibaba ra mắt mô hình AI Qwen2-VL có khả năng phân tích video dài hơn 20 phút
Alibaba Cloud, bộ phận dịch vụ đám mây và lưu trữ của gã khổng lồ thương mại điện tử Trung Quốc, đã công bố phát hành Qwen2-VL, mô hình ngôn ngữ hình ảnh tiên tiến mới nhất của hãng, được thiết kế để nâng cao khả năng hiểu hình ảnh, video và xử lý văn bản-hình ảnh đa ngôn ngữ.
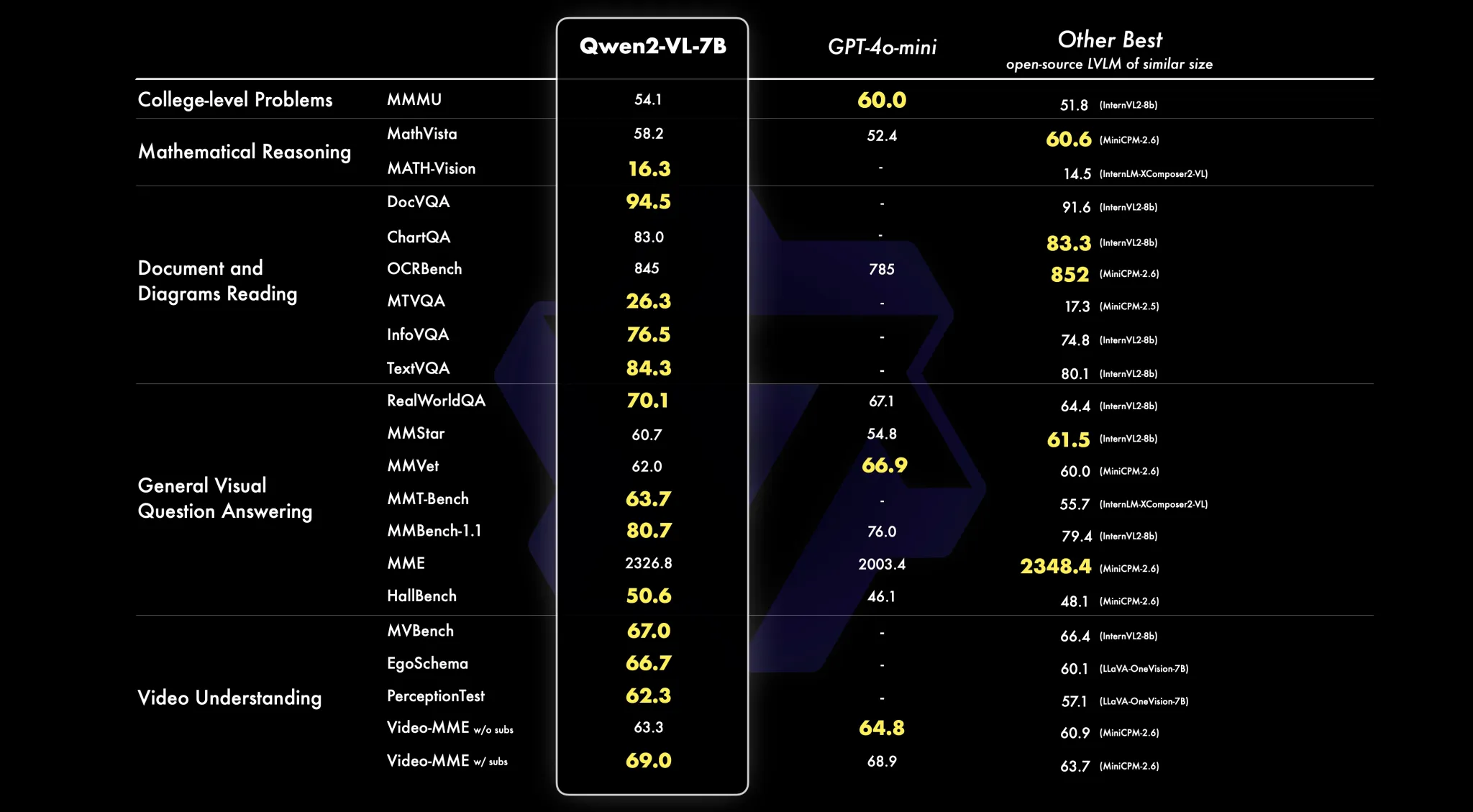
Và so với các mô hình tiên tiến hàng đầu khác như Llama 3.1 của Meta, GPT-4o của OpenAI, Claude 3 Haiku của Anthropic và Gemini-1.5 Flash của Google, Qwen2-VL đã tự hào có hiệu suất ấn tượng trong các bài kiểm tra benchmark của bên thứ ba. Bạn có thể thử suy luận về mô hình này được lưu trữ ở đây trên Hugging Face. https://huggingface.co/spaces/Qwen/Qwen2-VL Các ngôn ngữ được hỗ trợ bao gồm tiếng Anh, tiếng Trung, hầu hết các ngôn ngữ châu Âu, tiếng Nhật, tiếng Hàn, tiếng Ả Rập và tiếng Việt.
Khả năng đặc biệt trong phân tích hình ảnh và video, thậm chí hỗ trợ kỹ thuật trực tiếp
Với Qwen-2VL mới, Alibaba đang tìm cách thiết lập các tiêu chuẩn mới cho sự tương tác của mô hình AI với dữ liệu trực quan, bao gồm khả năng phân tích và phân biệt chữ viết tay ở nhiều ngôn ngữ, xác định, mô tả và phân biệt giữa nhiều đối tượng trong ảnh tĩnh, và thậm chí phân tích video trực tiếp gần thời gian thực, cung cấp tóm tắt hoặc phản hồi có thể mở ra cánh cửa để sử dụng cho hỗ trợ kỹ thuật và các hoạt động trực tiếp hữu ích khác.
Như nhóm nghiên cứu Qwen đã viết trong một bài đăng trên blog trên GitHub về họ mô hình Qwen2-VL mới: “Ngoài hình ảnh tĩnh, Qwen2-VL còn mở rộng khả năng của mình sang phân tích nội dung video. Nó có thể tóm tắt nội dung video, trả lời các câu hỏi liên quan đến video đó và duy trì luồng hội thoại liên tục trong thời gian thực, cung cấp hỗ trợ trò chuyện trực tiếp. Chức năng này cho phép nó hoạt động như một trợ lý cá nhân, giúp người dùng bằng cách cung cấp thông tin chi tiết và thông tin được rút ra trực tiếp từ nội dung video.”
Ngoài ra, Alibaba còn tự hào rằng mô hình này có thể phân tích video dài hơn 20 phút và trả lời các câu hỏi về nội dung.
Alibaba thậm chí còn đưa ra một ví dụ về mô hình mới phân tích và mô tả chính xác video sau:
Đây là phần tóm tắt của Qwen-2VL: Video bắt đầu bằng cảnh một người đàn ông đang nói chuyện với máy quay, tiếp theo là một nhóm người đang ngồi trong phòng điều khiển. Sau đó, máy quay chuyển sang cảnh hai người đàn ông đang lơ lửng bên trong trạm vũ trụ, nơi họ được nhìn thấy đang nói chuyện với máy quay. Những người đàn ông này dường như là phi hành gia và họ đang mặc bộ đồ du hành vũ trụ. Trạm vũ trụ chứa đầy đủ các thiết bị và máy móc khác nhau, và máy quay lia xung quanh để hiển thị các khu vực khác nhau của trạm. Những người đàn ông tiếp tục nói chuyện với máy quay và họ dường như đang thảo luận về nhiệm vụ của mình và các nhiệm vụ khác nhau mà họ đang thực hiện. Nhìn chung, video cung cấp cái nhìn tổng quan hấp dẫn về thế giới khám phá không gian và cuộc sống hàng ngày của các phi hành gia.
Ba kích thước, hai trong số đó là hoàn toàn mã nguồn mở theo giấy phép Apache 2.0
Mô hình mới của Alibaba có ba biến thể với các kích thước tham số khác nhau — Qwen2-VL-72B (72 tỷ tham số), Qwen2-VL-7B và Qwen2-VL-2B. (Lưu ý rằng tham số mô tả cài đặt bên trong của mô hình, với nhiều tham số thường thể hiện mô hình mạnh hơn và có khả năng hơn.)
Các biến thể 7B và 2B có sẵn theo giấy phép Apache 2.0 cho phép nguồn mở, cho phép các doanh nghiệp sử dụng chúng theo ý muốn cho mục đích thương mại, khiến chúng trở thành lựa chọn hấp dẫn cho những người ra quyết định tiềm năng. Chúng được thiết kế để mang lại hiệu suất cạnh tranh ở quy mô dễ tiếp cận hơn và có sẵn trên các nền tảng như Hugging Face và ModelScope.
Tuy nhiên, mô hình 72B lớn nhất vẫn chưa được phát hành công khai và sẽ chỉ được cung cấp sau này thông qua giấy phép và giao diện lập trình ứng dụng (API) riêng biệt từ Alibaba.
Gọi hàm và nhận thức trực quan giống con người
Sê-ri Qwen2-VL được xây dựng dựa trên nền tảng của họ mô hình Qwen, mang đến những tiến bộ đáng kể trong một số lĩnh vực chính:
Các mô hình có thể được tích hợp vào các thiết bị như điện thoại di động và rô-bốt, cho phép vận hành tự động dựa trên môi trường trực quan và hướng dẫn văn bản.
Tính năng này làm nổi bật tiềm năng của Qwen2-VL như một công cụ mạnh mẽ cho các tác vụ đòi hỏi khả năng lập luận và ra quyết định phức tạp.
Ngoài ra, Qwen2-VL còn hỗ trợ gọi hàm — tích hợp với phần mềm, ứng dụng và công cụ của bên thứ ba khác — và trích xuất thông tin trực quan từ các nguồn thông tin bên thứ ba này. Nói cách khác, mô hình có thể xem xét và hiểu “trạng thái chuyến bay, dự báo thời tiết hoặc theo dõi gói hàng” mà Alibaba cho biết điều này giúp mô hình có khả năng “tạo điều kiện thuận lợi cho các tương tác tương tự như nhận thức của con người về thế giới.”
Qwen2-VL giới thiệu một số cải tiến về kiến trúc nhằm nâng cao khả năng xử lý và hiểu dữ liệu trực quan của mô hình.
Hỗ trợ Độ phân giải động ngây thơ cho phép các mô hình xử lý hình ảnh ở nhiều độ phân giải khác nhau, đảm bảo tính nhất quán và chính xác trong diễn giải trực quan. Ngoài ra, hệ thống Nhúng vị trí xoay đa phương thức (M-ROPE) cho phép các mô hình đồng thời nắm bắt và tích hợp thông tin vị trí trên văn bản, hình ảnh và video.
Điều gì tiếp theo cho Đội Qwen?
Đội Qwen của Alibaba cam kết tiếp tục nâng cao khả năng của mô hình ngôn ngữ hình ảnh, xây dựng dựa trên thành công của Qwen2-VL với kế hoạch tích hợp các phương thức bổ sung và tăng cường tiện ích của mô hình trên một loạt các ứng dụng rộng lớn hơn.
Các mô hình Qwen2-VL hiện đã sẵn sàng để sử dụng và Đội Qwen khuyến khích các nhà phát triển và nhà nghiên cứu khám phá tiềm năng của những công cụ tiên tiến này.